CPU vs GPU
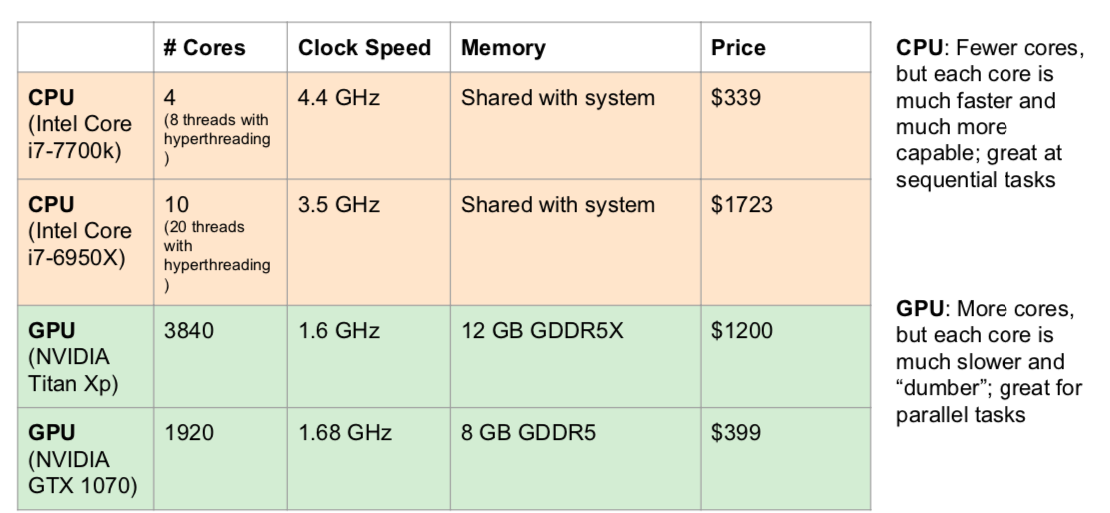

- CUDA: hard to write performat code, so use existing codes

Deep Learning Frameworks

- Numpy
- can’t run on GPU
- each expression must be completed to calculate gradients
- Tensorflow
- create forward computational graph
- ask TensorFlow to compute gradients
- tell TensorFlow to run on CPU or GPU
- PyTorch
- define Variables to start building a computational graph
- forward pass looks just like numpy
- calling c.backward() computes all gradients
- run on GPU by casting to ‘.cuda()’
- Numpy
- TensorFlow

- define model object as a sequence of layers
- define optimizer object
- build the model, specify loss function
- train the model with a single line
- Theano
- earlier framework from Montreal University
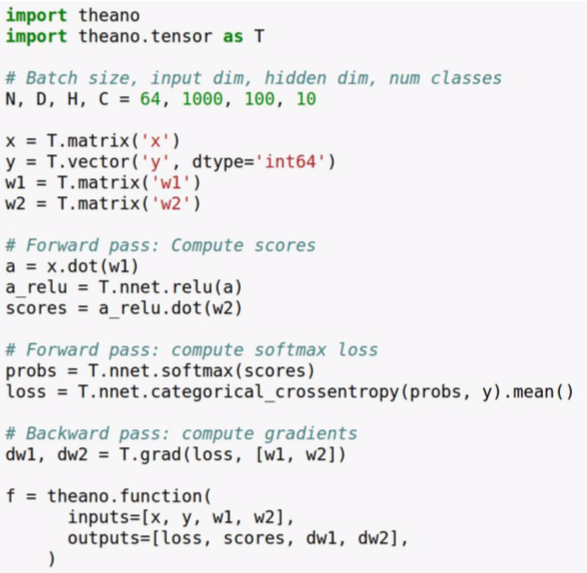
- define symbolic variables (similar to TensorFlow placeholder)
- forward pass: compute predictions and loss (no computation performed yet)
- ask Theano to compute gradients for us (no computation performed yet)
- compile a function that computes loss, scores, and gradients from data and weights
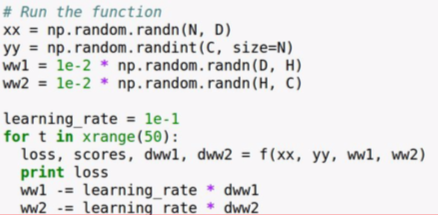
- run the function many times to train the network
- PyTorch
- abstraction
- Tensor: Imperative ndarray, but runs on GPU
- Variable: Node in a computational graph; stores data and gradient
- Module: A neural network layer; may store state or learnable weights
- Tensors

- to run on GPU, just cast tensors to a cuda datatype (dtype)
- create random tensors for data and weights
- forward pass: compute predictions and loss
- backward pass: manually compute gradients
- gradient descent step on weights
- Autograd

- x.data is a Tensor
- x.grad is a Variable of gradients (same shape as x.data)
- x.grad.data is a Tensor of gradients
- Variables remember how they were created (for backprop)
- forward pass looks exactly the same as the Tensor version, but everything is a variable now
- compute gradient of loss with respect to w1 and w2 (zero out grads first)
- make gradient step on weights
- nn
- higher-level wrapper

- define our model as a sequence of layers
- defines common loss functions
- forward pass: feed data to model, and prediction to loss function
- backward pass: compute all gradients
- make gradient step on each model parameter
- DataLoader
- wraps a Dataset and provides minibatching, shuffling, multithreading
- when you need to load custom data, just write your own Dataset class
- abstraction
- Static vs Dynamic Graphs

- Static
- once graph is built, can serialize it and run it without the code that built the graph
- good for reuse because the form is stored separately
- Dynamic
- graph building and execution are intertwined, so always need to keep code around
- bad for reuse

- convenient to use conditional expressions

- can be expressed simply when there is a Variable that varies in size every time
- Recurrent networks, Recursive networks, Modular Networks
- Caffe / Caffe2
- Core written in C++
- Has Python and MATLAB bindings
- Good for training or finetuning feedforward classification models
- Often no need to write code
- Convert data (run a script)
- Define net (edit prototxt): define a model
- Define solver (edit prototxt): define a SolverParameter
- Train (with pretrained weights) (run a script)
- Not used as much in research anymore, still popular for deploying models
- Caffe Model Zoo: has pre-trained models
- Pros / Cons
- (+) good for feedforward networks
- (+) good for finetuning existing networks
- (+) train models without writing any code
- (+) python interface is pretty useful
- (+) can deploy without Python
- (-) need to write C++ / CUDA for new GPU layers
- (-) not good for recurrent networks
- (-) cumbersome for big networks (GoogLeNet, ResNet)
- Summary
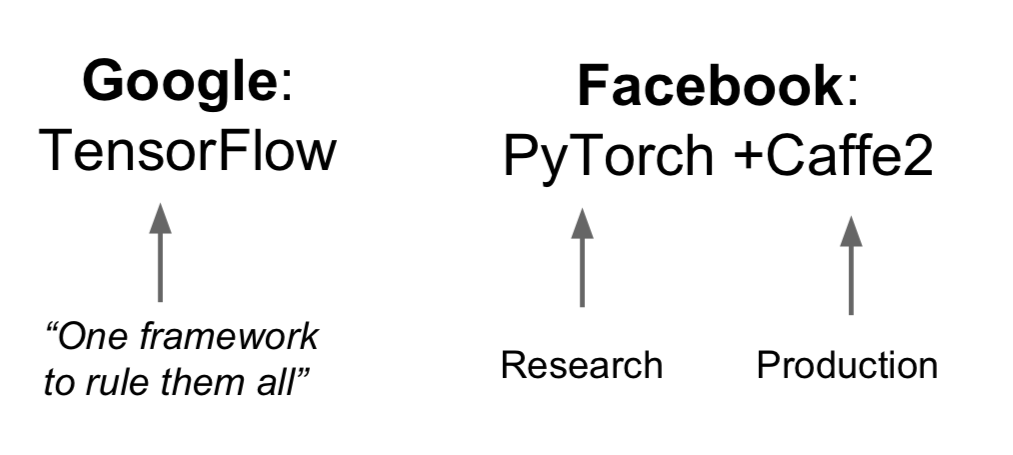
- TensorFlow is a safe, and use it for one graph over many machines
- PyTorch is good for research
This is written by me after taking CS231n Spring 2017 provided by Stanford University.
If you have questions, you can leave a reply on this post.