LeNet-5
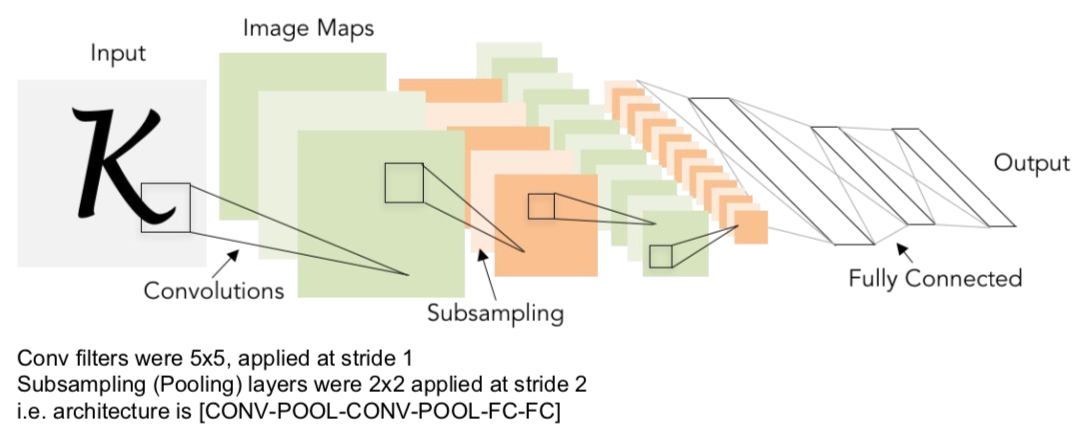
- early CNN model
AlexNet
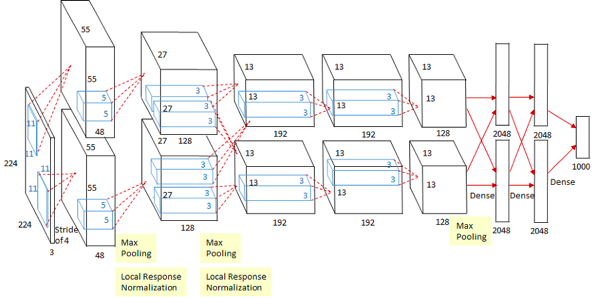
- input: 227 x 227 x 3 images (in the picture, it says 224, but 227 is correct)
- first layer (CONV 1): 96 11 x 11 filters, stride 4
- output volume size: (227 - 11) / 4 + 1 = 55 \(\rightarrow\) 96 x 55 x 55
- total number of parameters: 11 x 11 x 3 x 96 = 35K
- second layer (POOL1): 3 x 3 filters, stride 2
- output volume size: (55 - 3) / 2 + 1 = 27 \(\rightarrow\) 96 x 27 x 27
- total number of parameters: 0 (parameters are not required because only the largest values are selected in the pooling layer)
- using two GPUs as a limit of memory when creating AlexNet, the output volume size is actually 2 x 48 x 27 x 27
- connections
- only with feature maps on same GPU: CONV1, CONV2, CONV4, CONV5
- with all feature maps in preceding layer, communication across GPUs: CONV3, FC6, FC7, FC8
- details
- first use of ReLU
- used Norm layers (= Local Response Normalization)

- pixels in the same position at the activation map are normalized so that very large pixels do not affect the surroundings
- not common anymore
- heavy data augmentation
- dropout 0.5
- batch size 128
- SGD Momentum 0.9
- Learning rate 1e-2, reduced by 10 manually when val accuracy plateaus
- L2 weight decay 5e-4
- 7 CNN ensemble
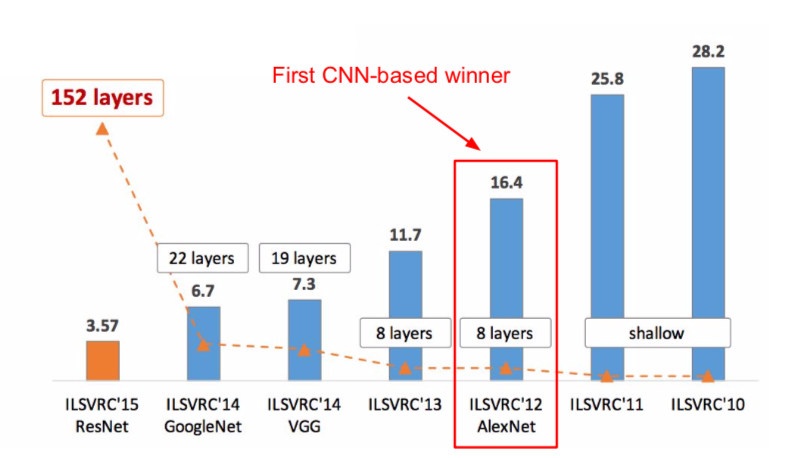
- performance
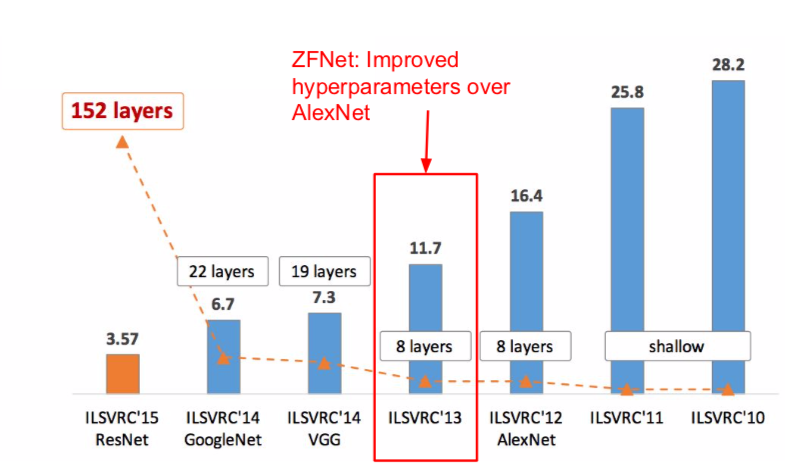
ZFNet
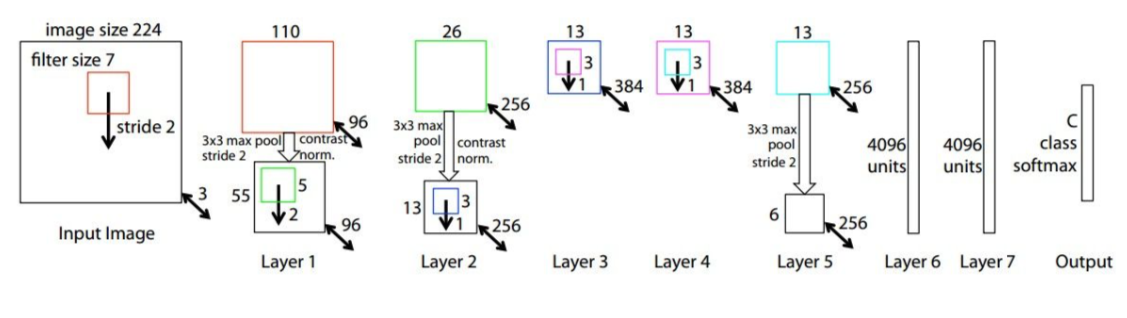
- Based on AlexNet, (11x11 stride 4) was changed to (7x7 stride 2) at CONV1, and 512, 1024, and 512 filters were used instead of 384, 384, and 256 at CONV3, 4, 5.
- perforamnce
VGGNet
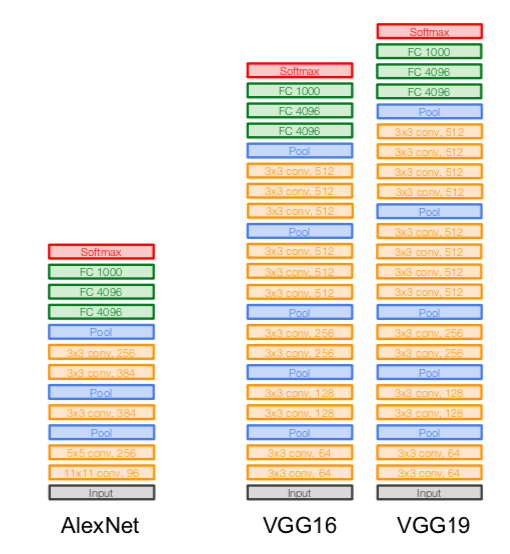
- small filters, deeper networks
- 16- 19 layers
- only 3 x 3 CONV stride 1, pad 1
- only 2 x 2 MAX POOL stride 2
- Q. Why use smaller filters? (3 x 3 CONV)
- stack of 3 3 x 3 conv (stride 1) layers has same effective receptive field as 1 7 x 7 conv layer, but deeper, more non-linearities, and fewer parameters: \(3 \times 3^2 \times C^2\) vs \(7^2 \times C^2 \ (C: input/output \ depth)\)

- because the number of parameters has increased a lot compared to AlexNet and each image takes up 96MB, it is not easy to handle a lot of pictures
- details
- ILSVRC’14 2nd in classification, 1st in localization (localization: drawing a bounding box)
- similar training procedure as AlexNet
- no Local Response Normalisation
- use VGG16 or VGG19 (VGG19 only slightly better, more memory, so VGG16 is more common)
- use ensembles for best results
- FC7 features generalize well to other tasks

- performance
GoogLeNet
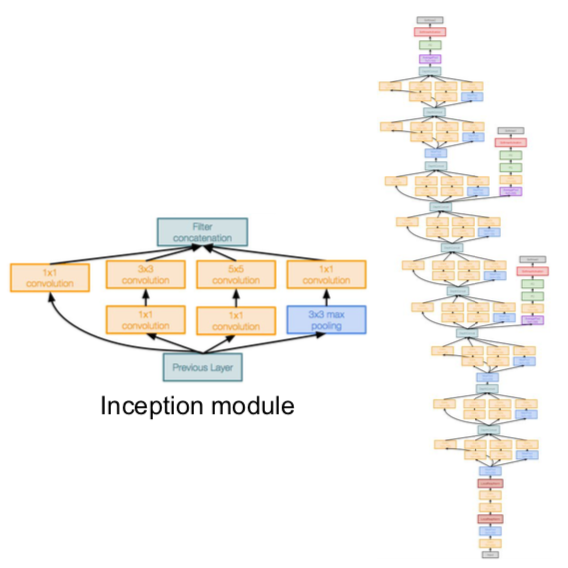
- deeper networks, with computational efficiency
- 22 layers
- efficient “Inception” module
- no FC layers \(\rightarrow\) the number of parameters could be greatly reduced
- only 5 million parameters (12x less than AlexNet)
- ILSVRC’14 classification winner (6.7% top 5 error)
- inceptional module
- design a good local network topology (network within a network) and then stack these modules on top of each other
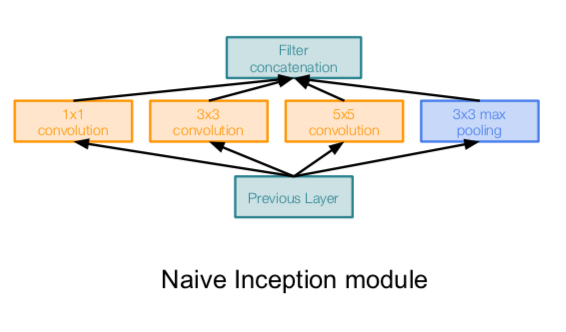
- apply parallel filter operations on the input from previous layer:
- multiple receptive field sizes for convolution (1x1, 3x3, 5x5)
- pooling operation (3x3)
- concatenate all filter outputs together depth-wise
- Q. What is the problem wtih this?
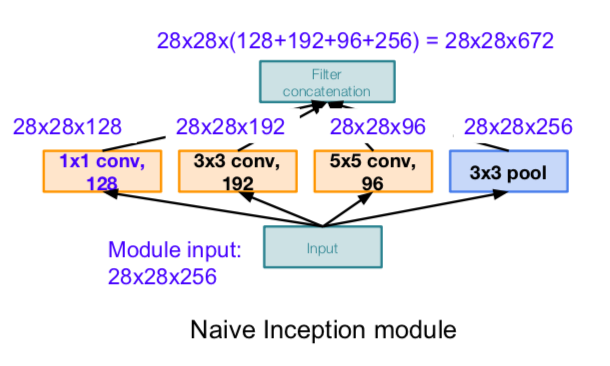
- because the depth value increases, the computation volume increases
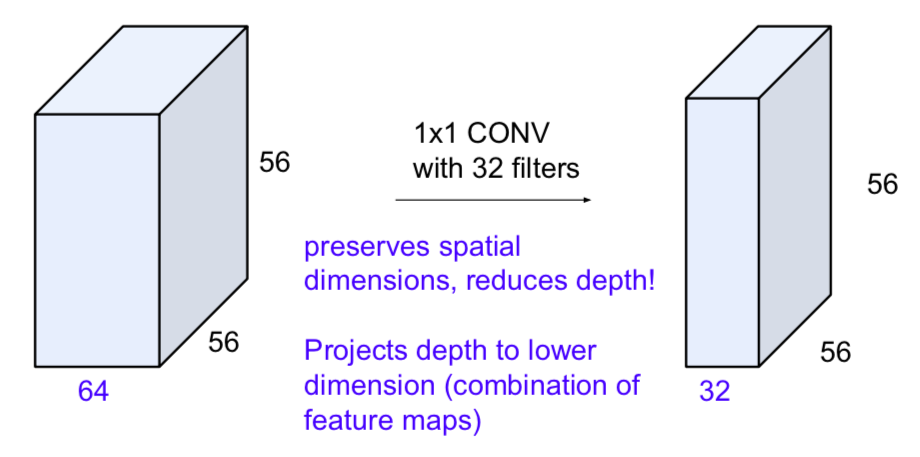
- Solution: “bottleneck” layers that use 1x1 convolutions to reduce feature depth
- apply parallel filter operations on the input from previous layer:
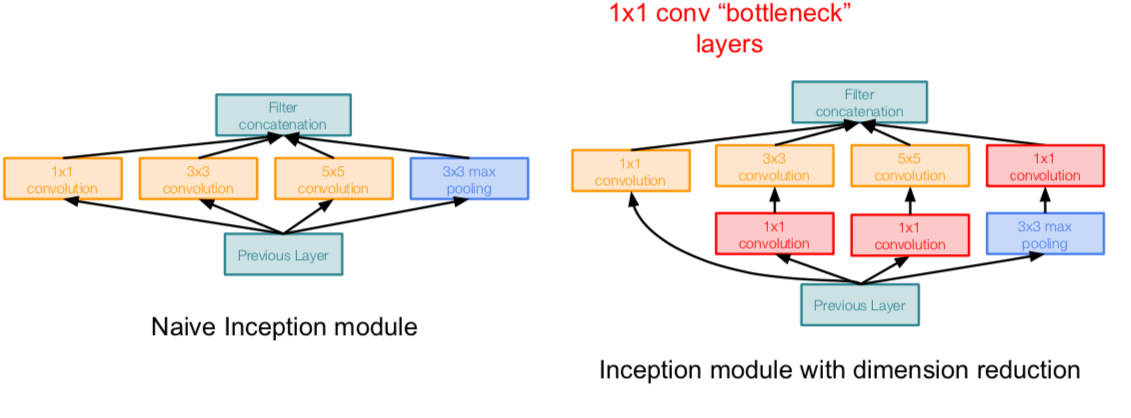
- the computational complexity has been greatly reduced
- there may be information loss due to 1 x 1 CONV, but there is an effect of removing redundancy and increasing non-linearity
- structure
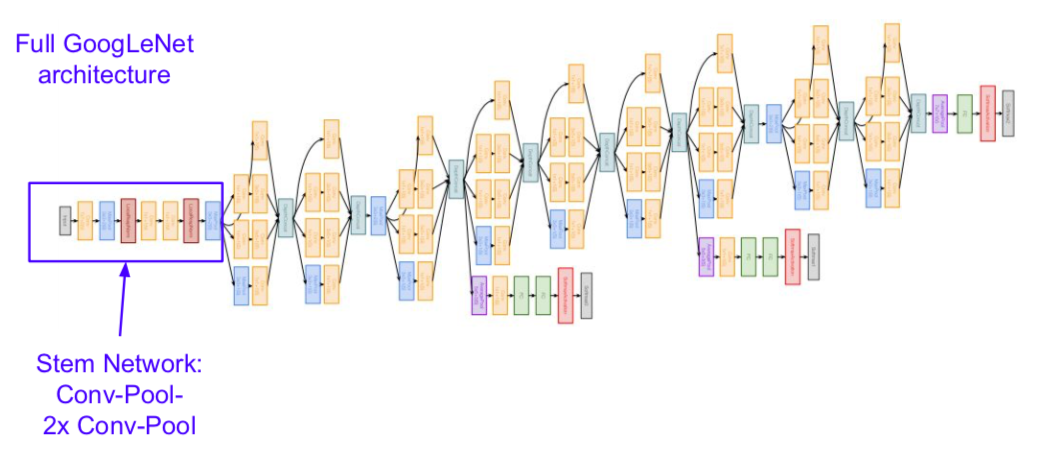
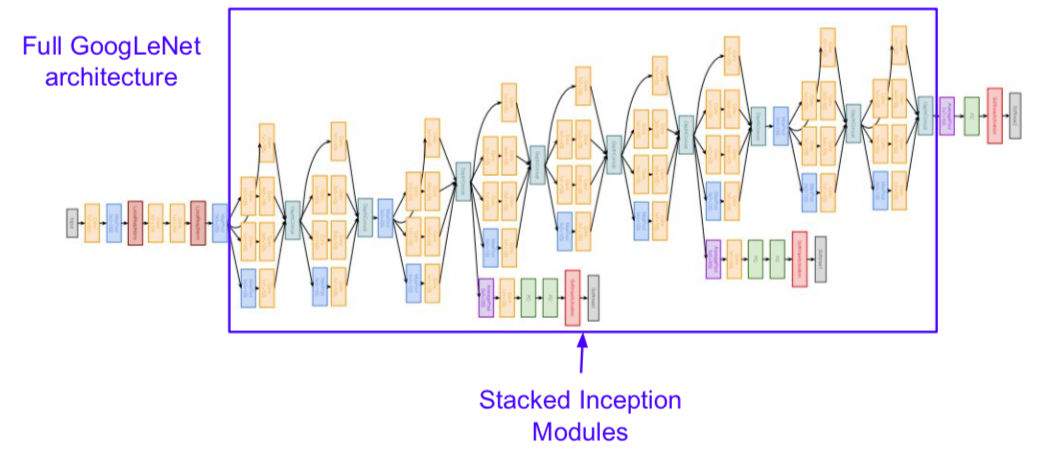

- used Global Average Pooling instead of Fully Connected
- to pool globally from the input value
- e.g) if an input of 7 x 7 x 1000 is given, the result of global average pooling is 1 x 1 x 1000
- then goes to the Fully Connected layer and the Softmax layer
- used Global Average Pooling instead of Fully Connected
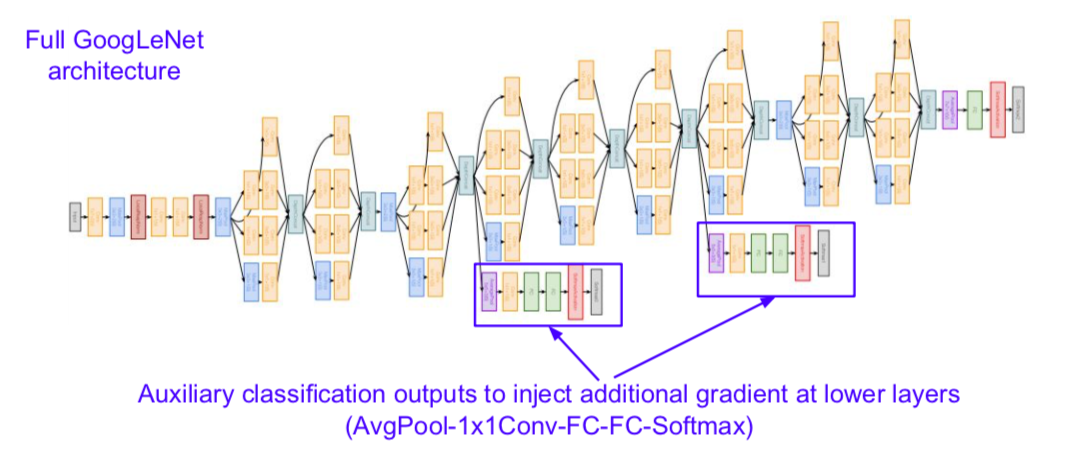
- adding additional gradients because the network is so deep that the gradients can be lost
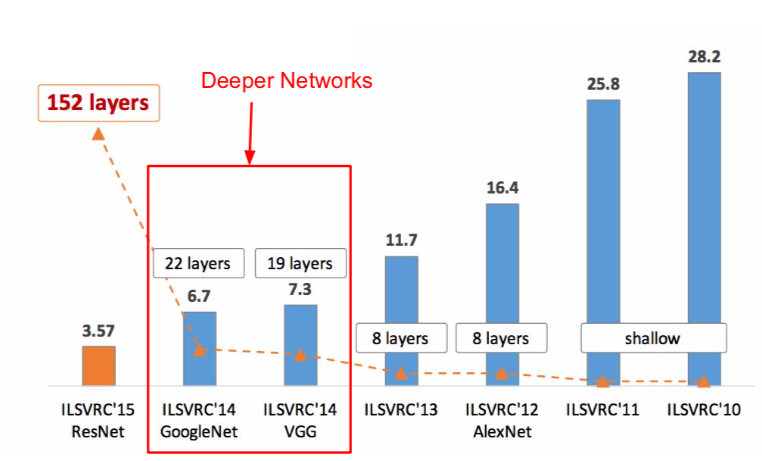
ResNet
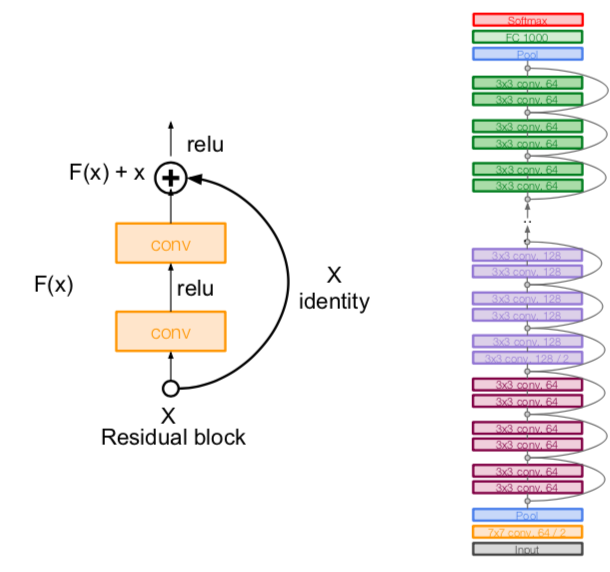
- very deep networks using residual connections
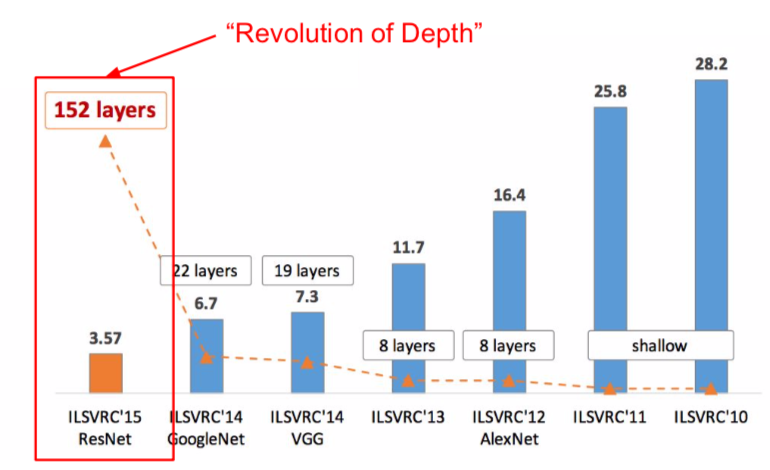
- 152-layer model for ImageNet
- ILSVRC’15 classification winner (3.57% top 5 error)
- swept all classification and detection competitions in ILSVRC’15 and COCO’15
- total depths of 34, 50, 101, or 152 layers for ImageNet
- Q. What happens when we continue stacking deeper layers on a plain convolutional neural network?
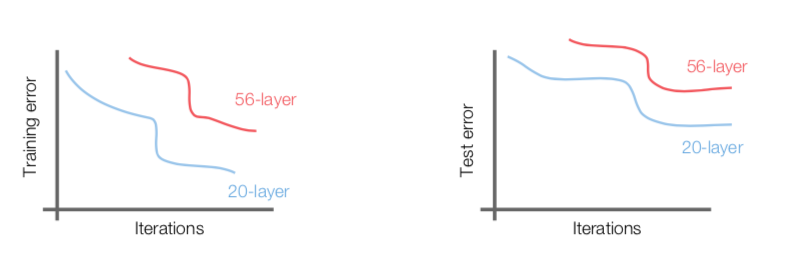
- The deeper model performs worse, but it’s not caused by overfitting
- the reason why it is not an overfitting is that the training error is not small
- performance
- solution: use network layers to fit a residual mapping instead of directly trying to fit a desired underlying mapping
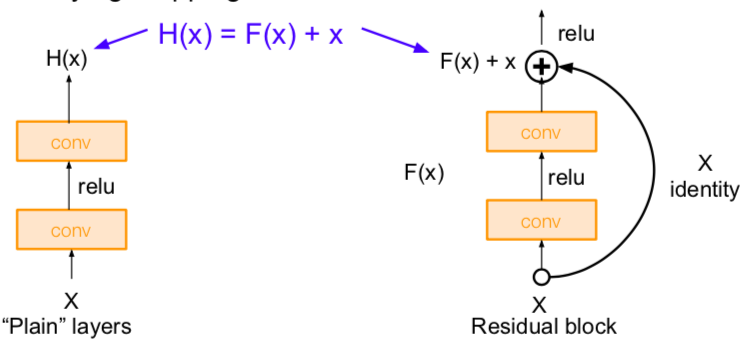
- use layers to fit residual F(x) = H(x) - x instead of H(x) directly
- that is, learning the residuals for input x
- architecture
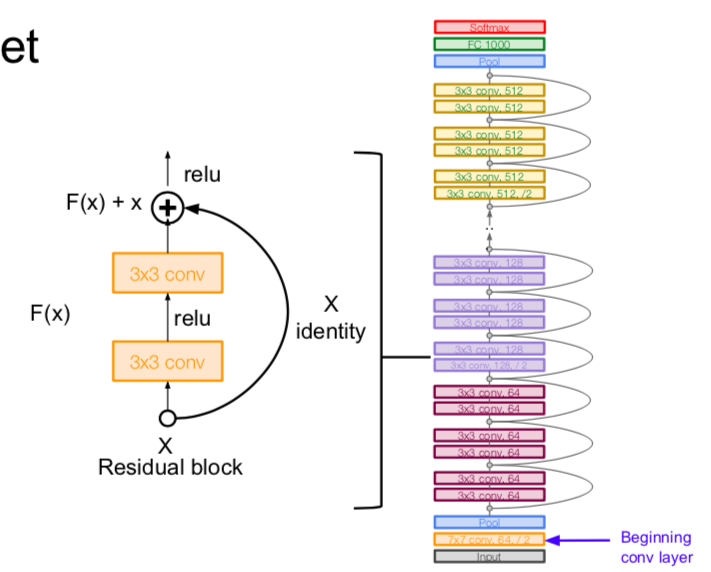
- additional conv layer at the beginning
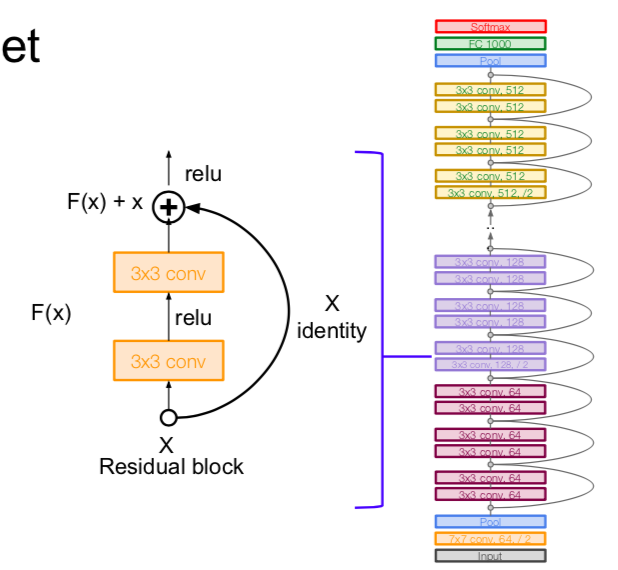
- stack residual blocks
- every residual block has two 3x3 conv layers
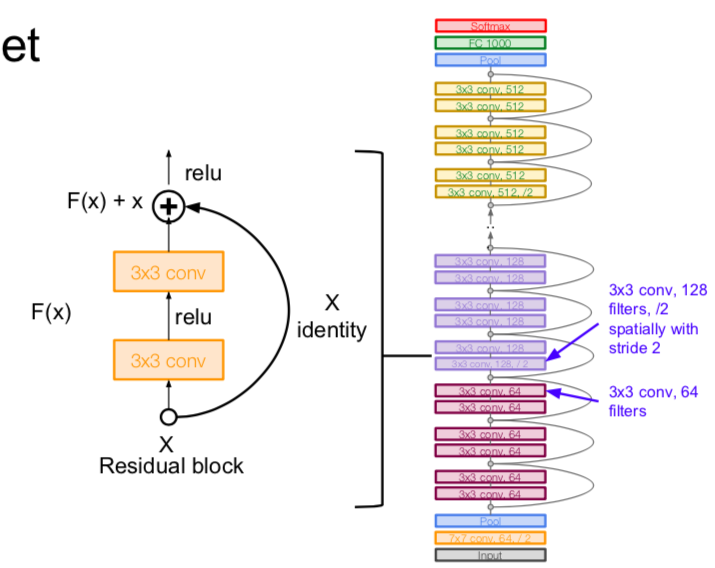
- periodically, double # of filters and downsample F(x) spatially using stride 2 (/2 in each dimension)
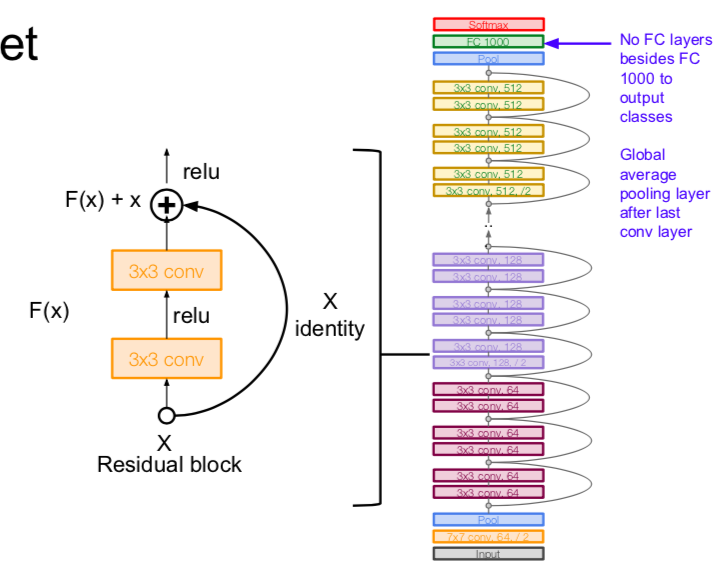
- use the global average pooling layer
- no FC layers at the end (only FC 1000 to output classes)
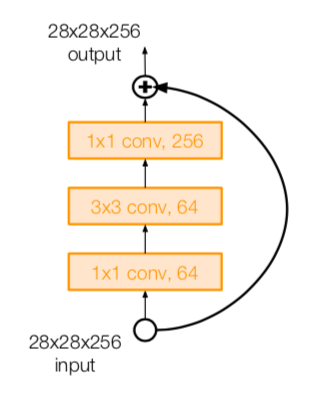
- for deeper networks (ResNet-50+), use “bottleneck” layer to improve efficiency (similar to GoogLeNet)
- performance
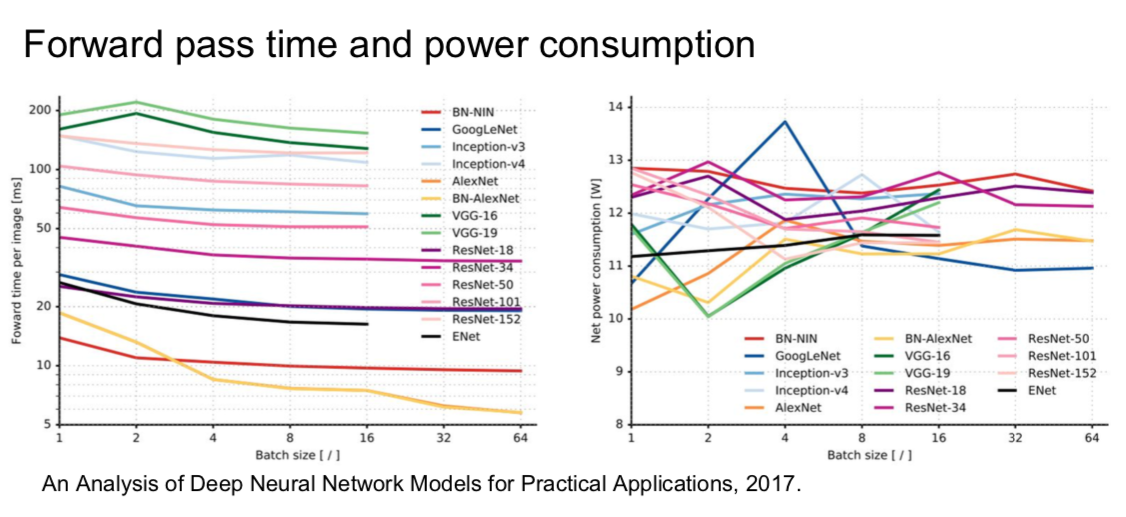
- training ResNet in practice
- batch Normalization after every CONV layer
- Xavier/2 initialization from He et al.
- SGD + Momentum (0.9)
- learning rate: 0.1, divided by 10 when validation error plateaus
- mini-batch size 256
- weight decay of 1e-5
- no dropout used
- experimental results
- able to train very deep networks without degrading (152 layers on ImageNet, 1202 on Cifar)
- deeper networks now achieve lowing training error as expected
- swept 1st place in all ILSVRC and COCO 2015 competitions
Comparing complexity
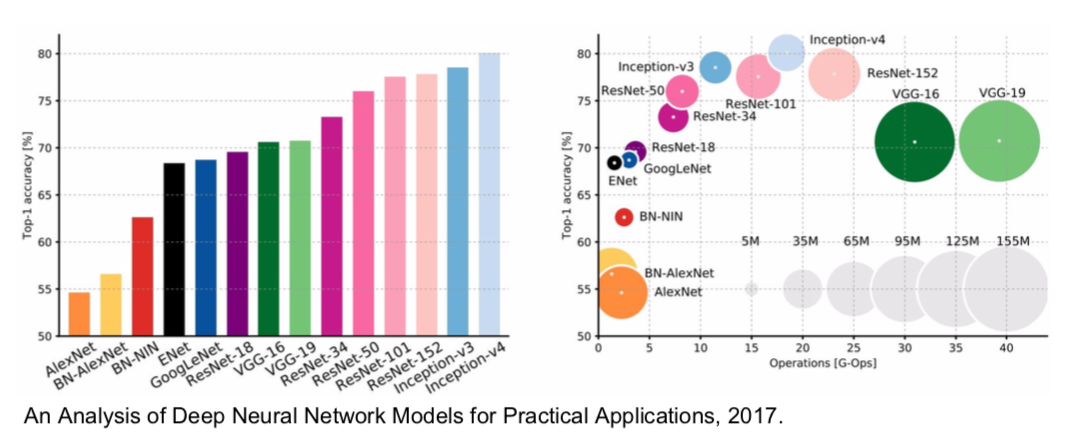
- Inception-v4: Resnet + Inception
- VGG: highest memory, most operations
- GoogLeNet: most efficient
- AlexNet: smaller compute, still memory heavy, lower accuracy
- ResNet: moderate efficiency depending on model, highest accuracy
Network in Network (NiN)
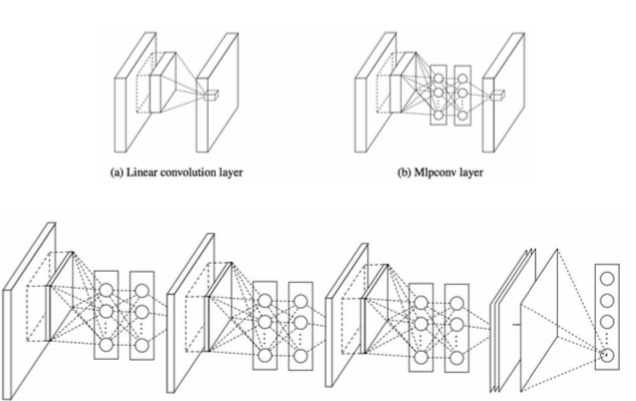
- Mlpconv layer with “micronetwork” within each conv layer to compute more abstract features for local patches
- micronetwork uses multilayer perceptron (FC, i.e. 1x1 conv layers)
- precursor to GoogLeNet and ResNet “bottleneck” layers
- philosophical inspiration for GoogLeNet
Identity Mappings in Deep Residual Networks
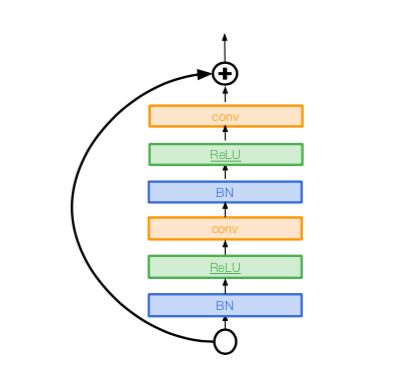
- improved ResNet block design from creators of ResNet
- creates a more direct path for propagating information throughout network (moves activation to residual mapping pathway)
- gives better performance
Wide Residual Networks

- argues that residuals are the important factor, not depth
- uses wider residual blocks (F x k filters instead of F filters in each layer)
- 50-layer wide ResNet outperforms 152-layer original ResNet
- increasing width instead of depth more computationally efficient (parallelizable)
Aggregated Residual Transformations for Deep Neural Networks (ResNeXt)
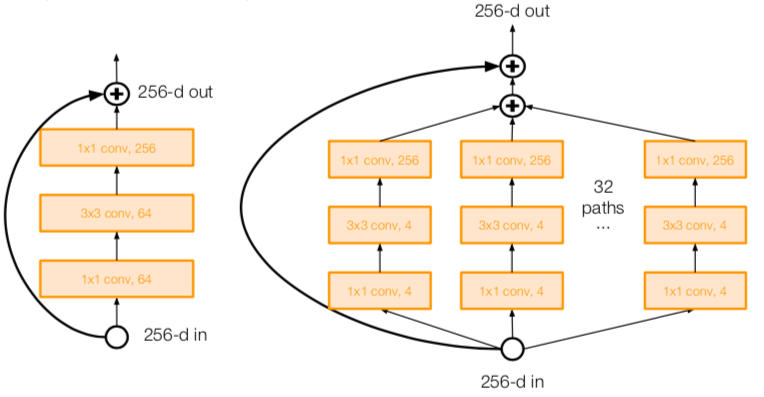
- also from creators of ResNet
- increases width of residual block through multiple parallel pathways (called “cardinality”)
- parallel pathways similar in spirit to Inception module
Deep Networks with Stochastic Depth
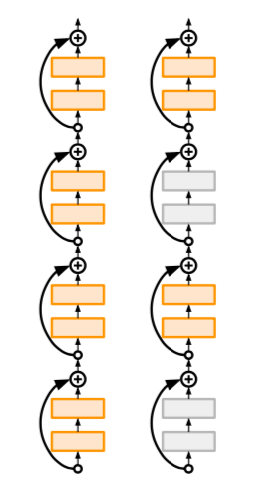
- motivation: reduce vanishing gradients and training time through short networks during training
- randomly drop a subset of layers during each training pass
- bypass with identity function
- use full deep network at test time
FractalNet: Ultra-Deep Neural Networks without Residuals
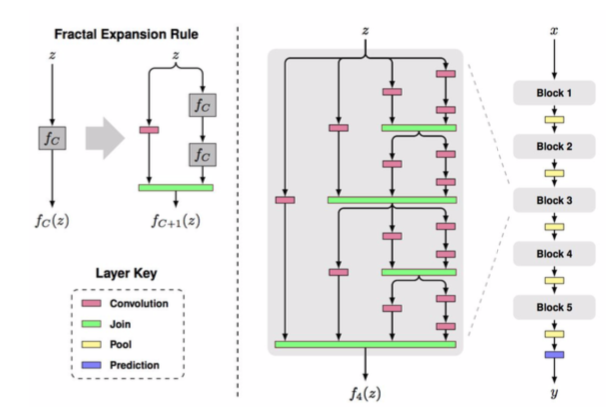
- argues that key is transitioning effectively from shallow to deep and residual representations are not necessary
- fractal architecture with both shallow and deep paths to output
- trained with dropping out sub-paths
- full network at test time
Densely Connected Convolutional Networks
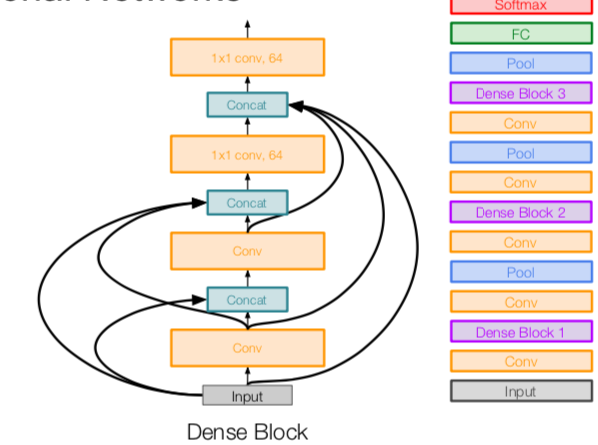
- dense blocks where each layer is connected to every other layer in feedforward fashion
- alleviates vanishing gradient, strengthens feature propagation, encourages feature reuse
SqueezeNet: AlexNet-level Accuracy With 50x Fewer Parameters and <0.5Mb Model Size
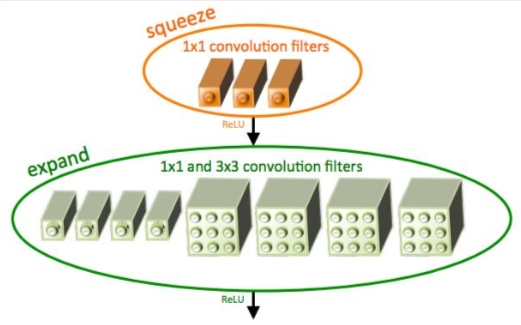
- fire modules consisting of a ‘squeeze’ layer with 1x1 filters feeding an ‘expand’ layer with 1x1 and 3x3 filters
- AlexNet level accuracy on ImageNet with 50x fewer parameters
- can compress to 510x smaller than AlexNet (0.5Mb)
Summary
- VGG, GoogLeNet, ResNet all in wide use, available in model zoos
- ResNet current best default
- trend towards extremely deep networks
- significant research centers around design of layer / skip connections and improving gradient flow
- even more recent trend towards examining necessity of depth vs width and residual connections
This is written by me after taking CS231n Spring 2017 provided by Stanford University.
If you have questions, you can leave a reply on this post.