Vanila Neural Network vs Recurrent Neural Networks
- vanila neural network
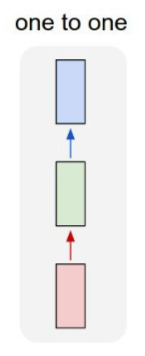
- there are limits to a fixed length of input and output
- RNN
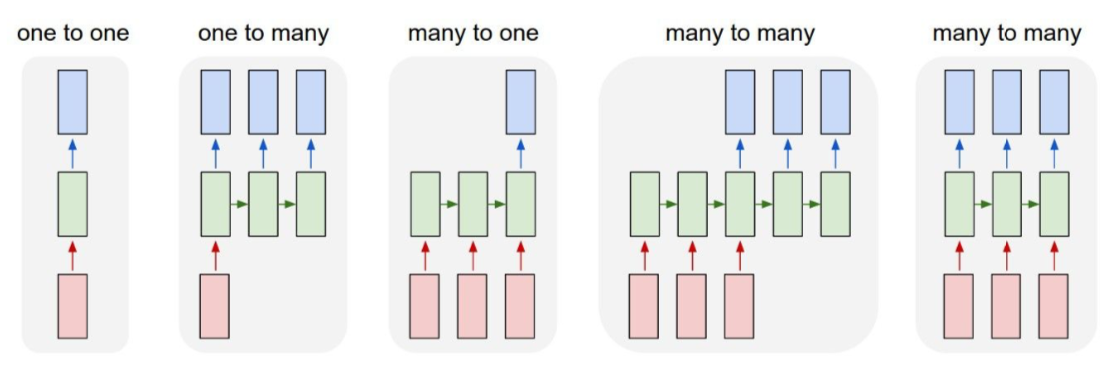
- e.g.
- one to many: image captioning
- many to one: sentiment calssification
- many to many: machine translation, video classification on frame level
- e.g.
Recurrent Neural Network
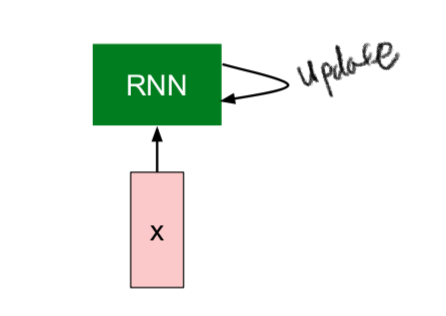
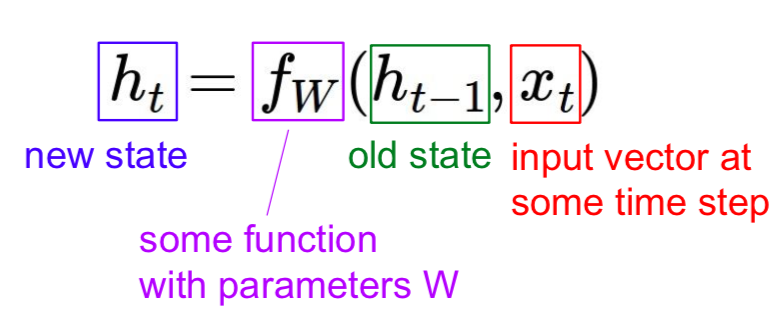
- the same function and the same set of parameters are used at every time step
- Vanila Recurrent Neural Network
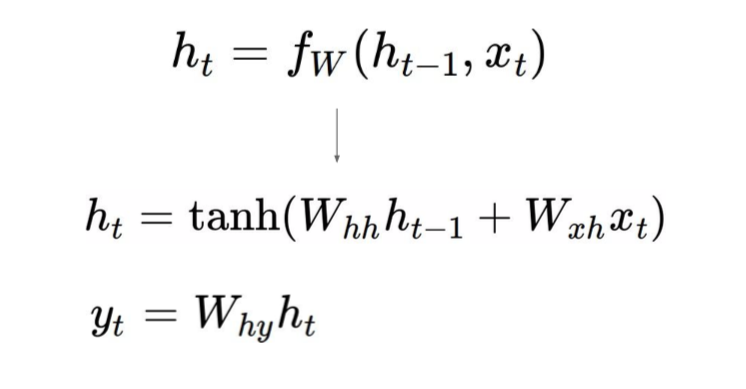
- \(W_{hh}\): weight from hidden state
- \(W_{xh}\): weight from x
- \(W_{hy}\): weight to y
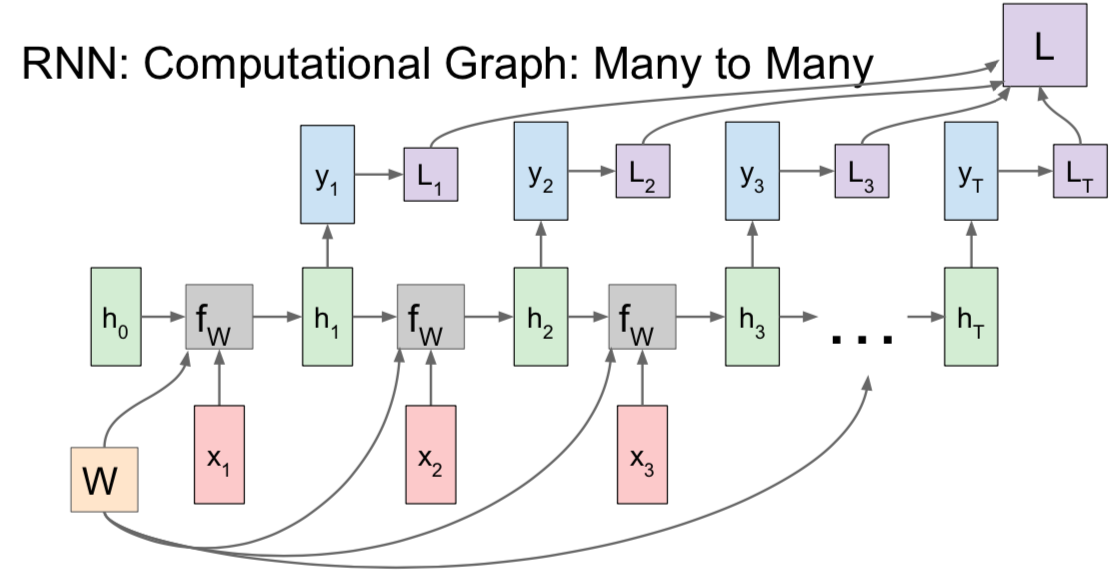
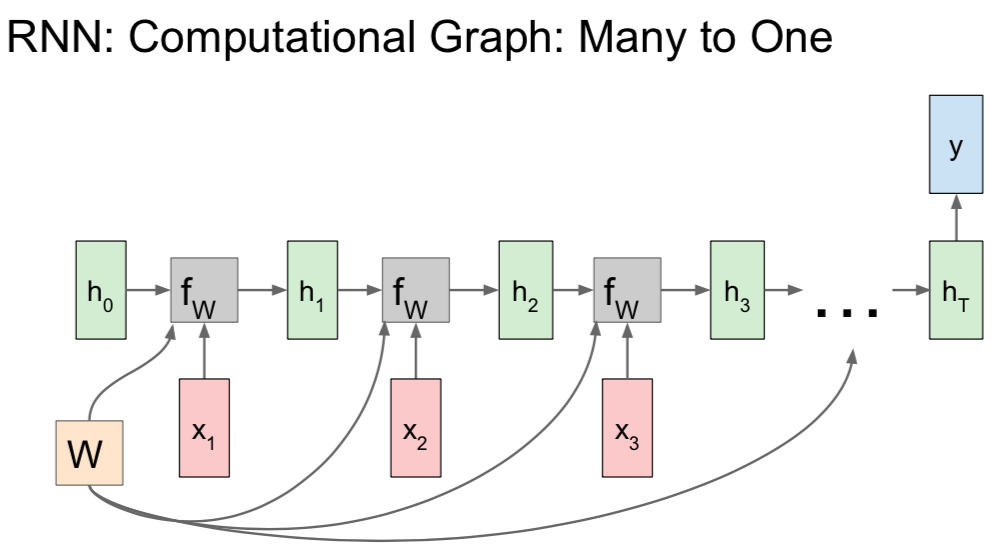
- \(h_T\): final hidden state \(\rightarrow\) summarizes all of the context
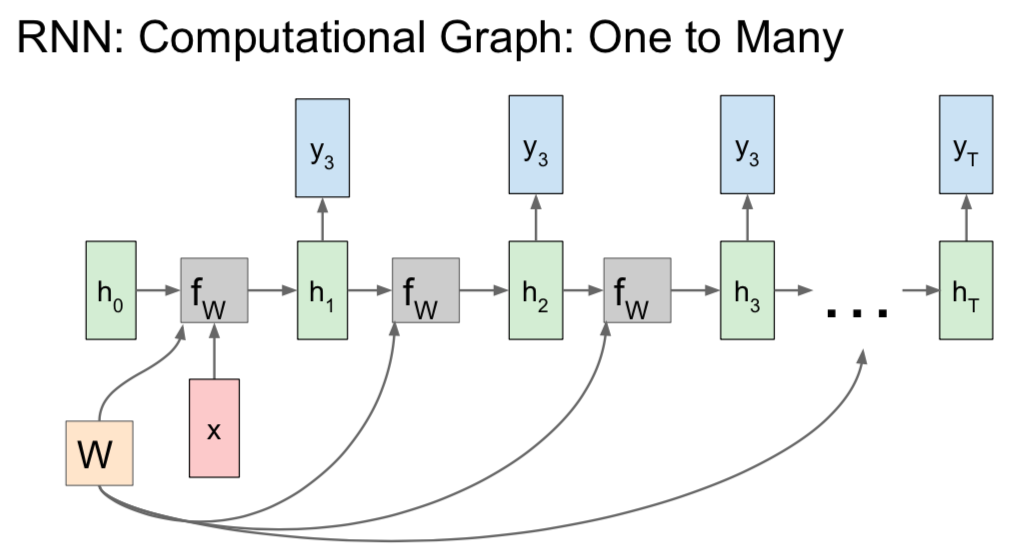
- a fixed input initializes the initial hidden state of the model
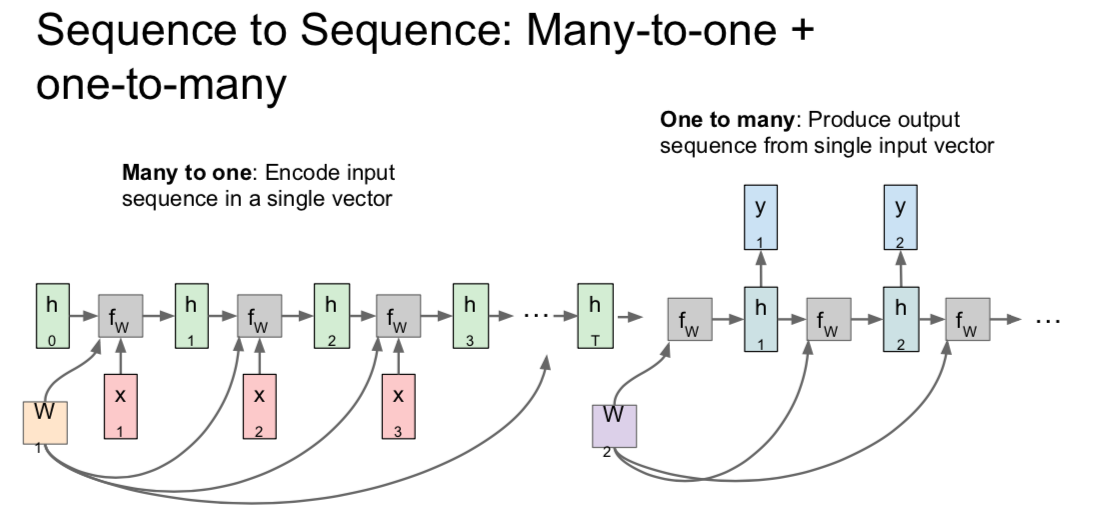
- encoder: take variable inputs and summarize the whole thing at the end
- decoder: make a variable output from the summarized data
- Example: Characeter-level Language Model
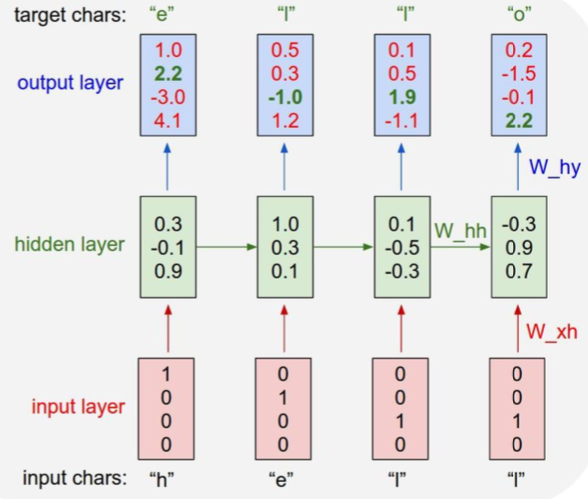
- vocabulary: [h, e, l, o]
- training sequence: “hello”
- values of output layers are not close to correct values, but after training by calculating loss values, the values of the correct characters increase
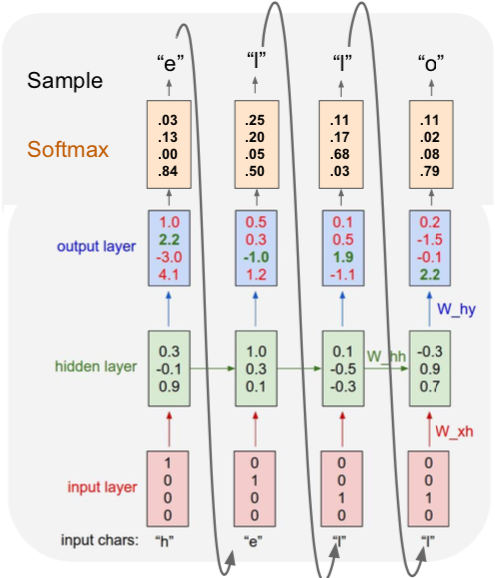
- when test-time was given an input of “h”, “e” was selected
- “e” becomes the input of the next step and passes through the model, creating a new output and continuing
- for the first time, the softamx value is “o” the largest, but luckily “e” is selected.
- for this problem, test-time does not select the alphabet with the highest softmax value, but sampling (random selection of one by probability)
- in general, sampling lets get diversity from the model
- Truncated Backpropagation through time
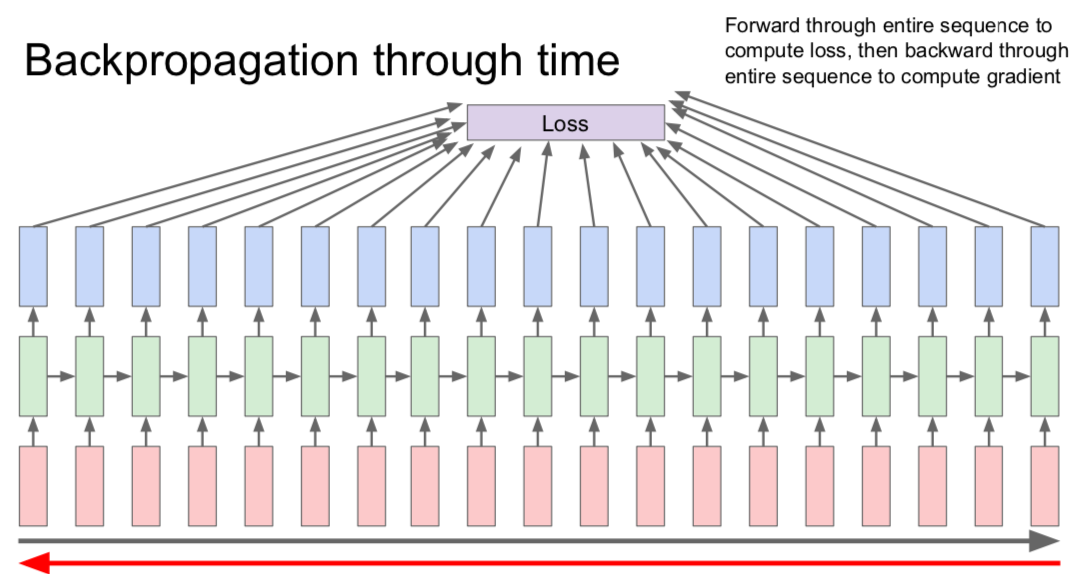
- if the data is large, there is a problem of slowing down
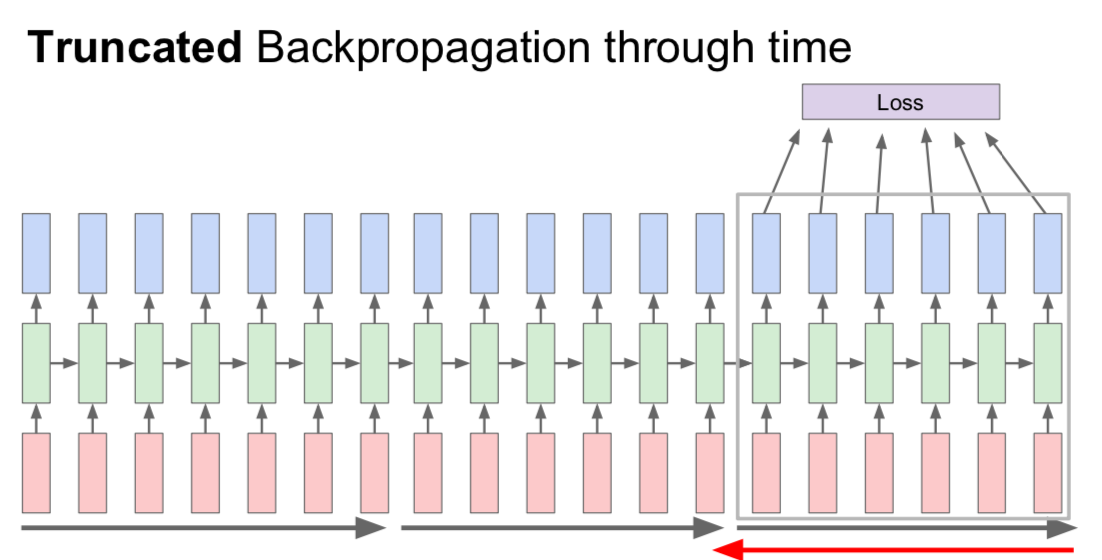
- run forward and backward through chunks of the sequence instead of whole sequence
- carry hidden states forward in time forever, but only backpropagate for some smaller number of steps
Image Captioning
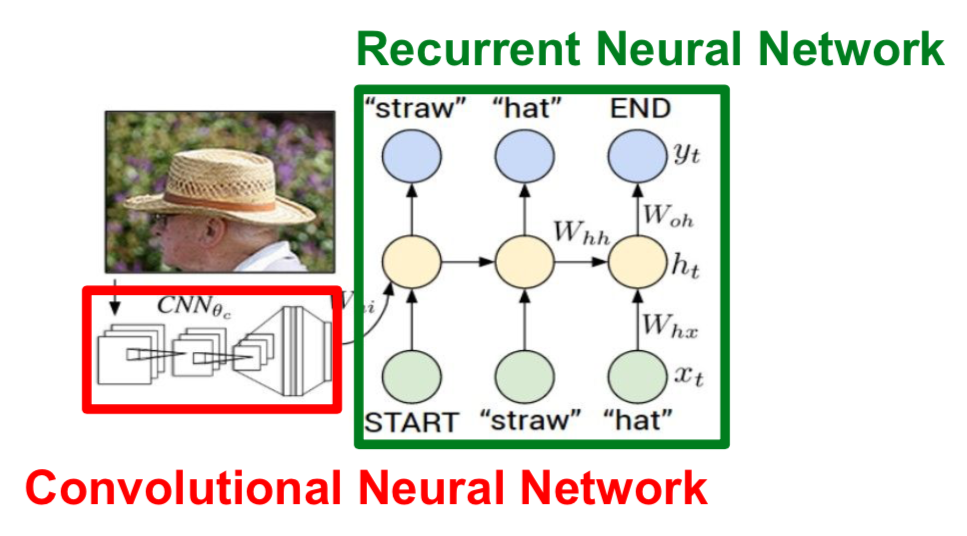
- a vector containing information in the image is obtained through CNN, and a sentence is generated through RNN

- the softmax at the end of the CNN model is eliminated, and a vector containing the entire degree of the image is generated through the fc-4096 layer
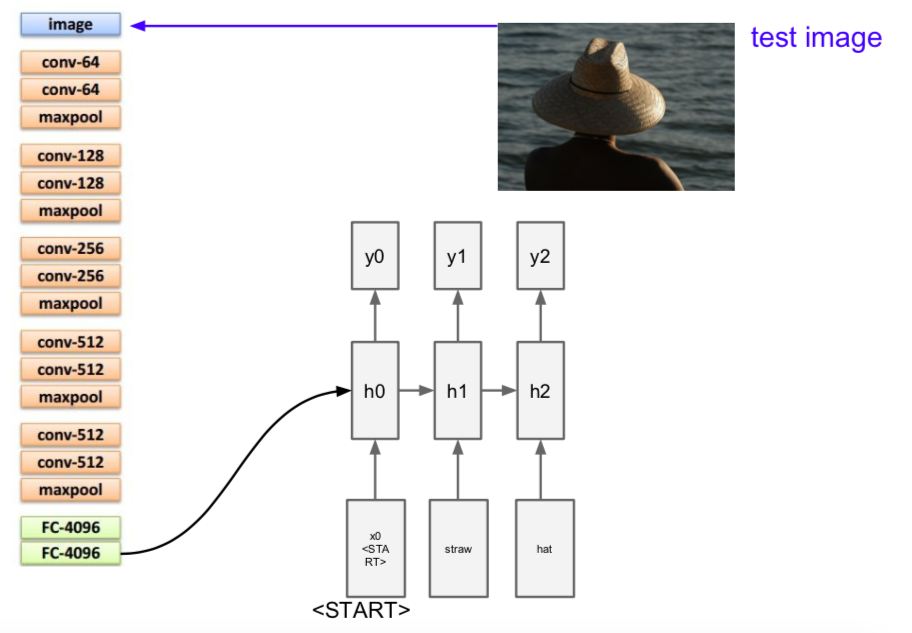
- needs start token to start
- calculated by sending vector information obtained from CNN to h0
- one output is the input of the next step
- RNN ends when end token is created (e.g. y2)
Attention
- Image Captioning
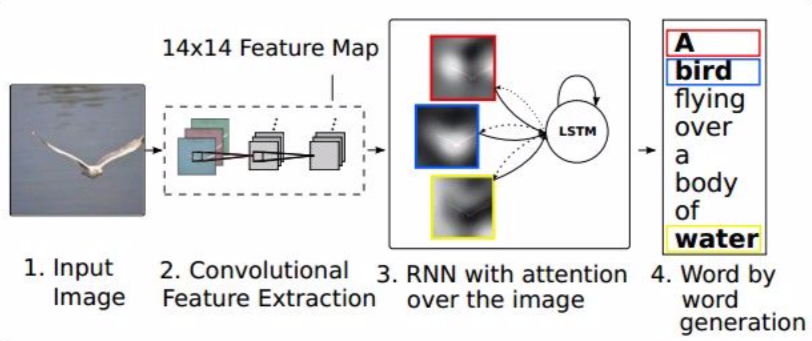
- RNN focuses its attention at a different spatial location when generating each word
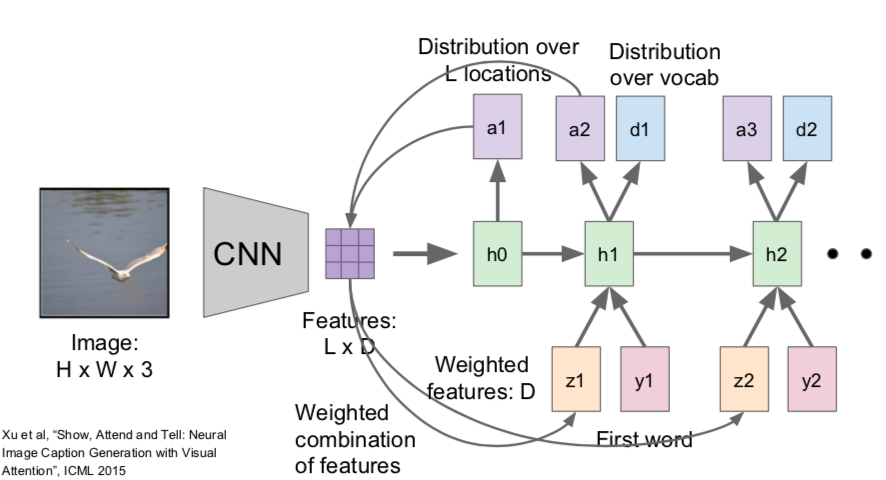
- h0: create a distribution of the location to concentrate in the image (a1)
- a1: computes the original vector (L \(\times\) D) to create an attention (z1)
- z1 and the first word(y1) enter h1 and a2 and distribution over vocabularay words (d1) are created
- results

- soft attention: take a weighted combination of all features from all image locations
- hard attention: select exactly one location to look at in the image at each time step

- Visual Question Answering

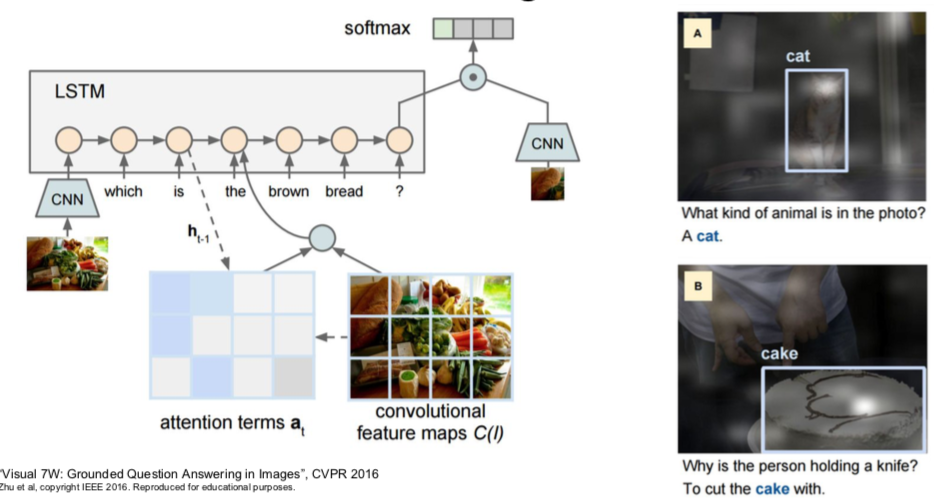
- get a summary of the image via CNN and a summary of the input question via RNN
- predict the correct answer through the obtained summaries
LSTM
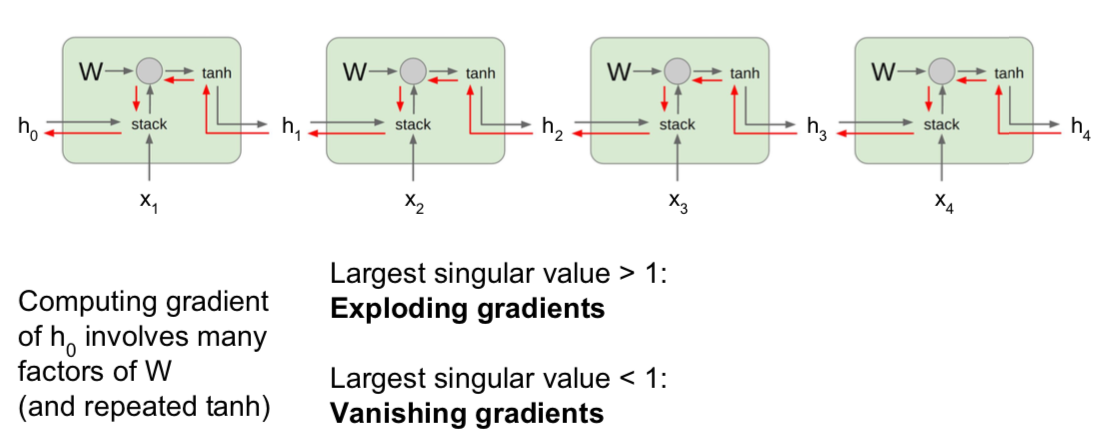

- problems arise as the weights continue to multiply
- when weights are large, it can be solved by gradient clipping, which is using normalizing, but when they are small, there is only a way to change RNN architecture
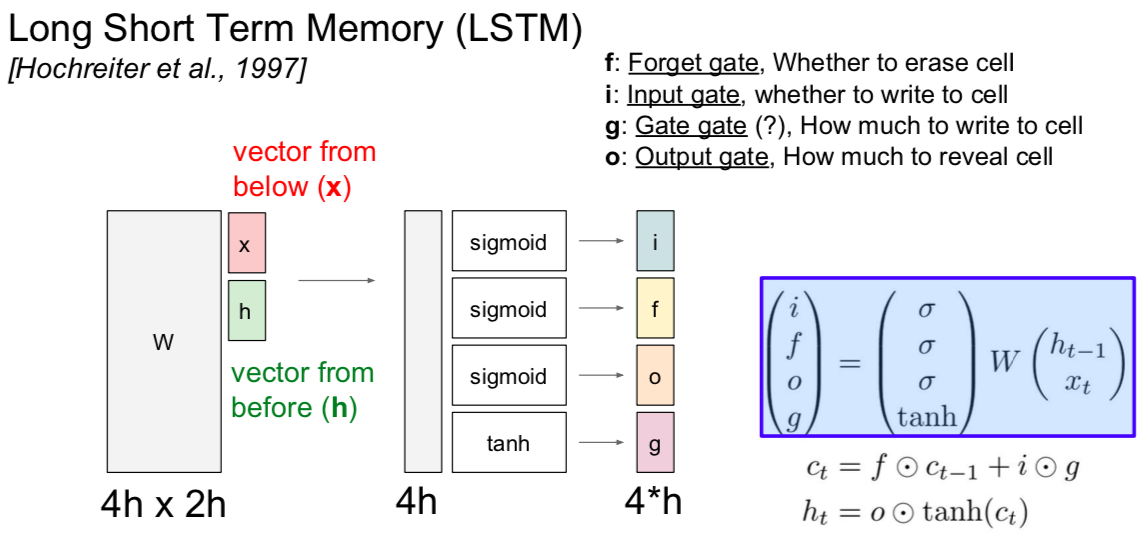
- g: determine how much input cell will be included
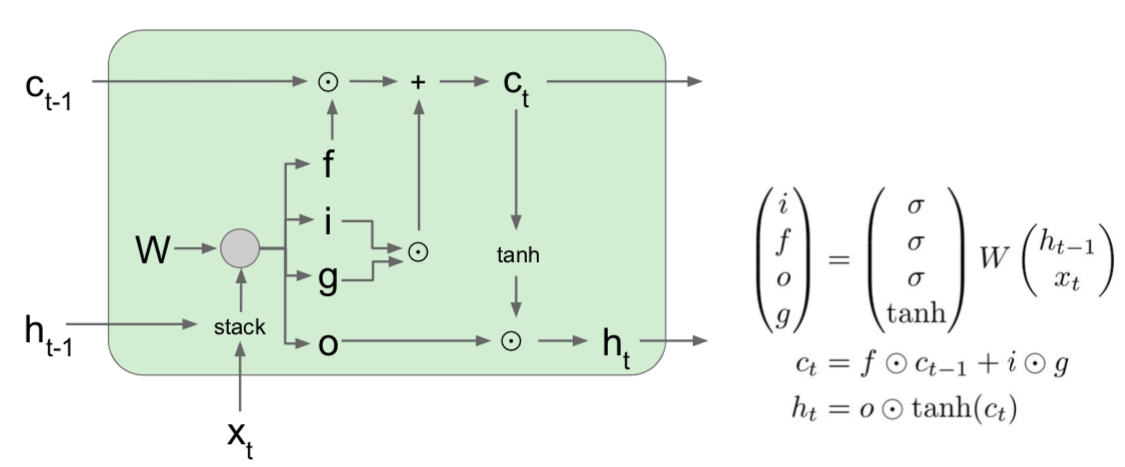

- Backpropagation from \(c_t\) to \(c_{t-1}\) only elementwise c multiplication by f, no matrix t multiply by W
This is written by me after taking CS231n Spring 2017 provided by Stanford University.
If you have questions, you can leave a reply on this post.